Taming the observability maze

Introduction Last week we wrote about how bi(OS) was hit with the load equivalent to two black Fridays on Thursday by tier-1 global retailers during Black Friday. While we are proud of our achievement, we don’t take our customers’ reliability for granted. Although, we do take a significantly different approach. Read on to learn why […]
Taming the non-deterministic Cloud
The TL;DR summary Over a 12+ hour run, bi(OS)’s real-time OLAP engine delivered a p99 latency of 1.46ms for inserts, 2.94ms for selects at a peak throughput of 21.5K rows/sec with an 80:20 write: read split for 1KB rows when the system is 70%+ utilized. Writes followed ⅔ QUORUM durability across three availability zones, reads […]
Who is M/F? Real World Data Quality

My blog last week talked about Schema lost in transit. Let me tell you a real story about a customer. We uploaded data from their repository into bi(OS) and the image above is a screenshot of what we saw on bi(OS) after an hour. We were not surprised as we have seen this story at […]
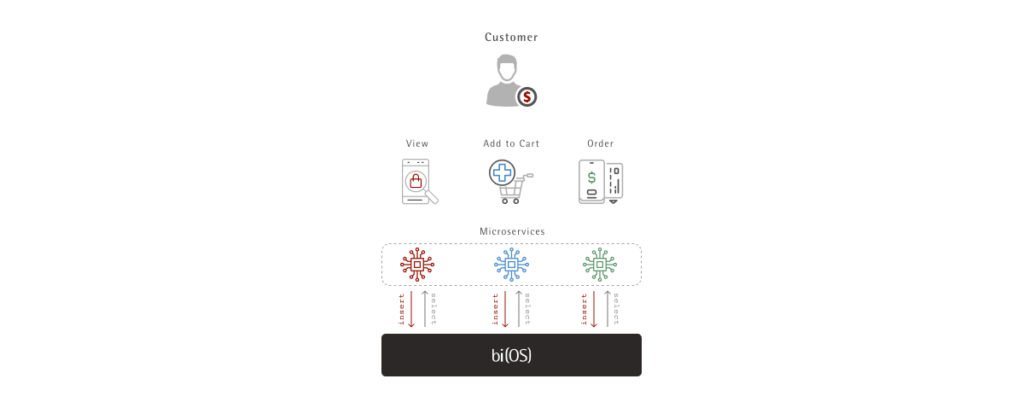
Schema lost in transit only to recreate again. WT*?

The current state of the art for Data Engineers is to build pipelines that ingest structured and semi-structured data in JSON, CSV, AVRO and store these as BLOBs on S3 (where the schema is lost). Then “Schema on Read” technologies such as Snowflake, Dremio or Presto process these BLOBs by (re)-applying the schema that was […]