
Authors: Mayur Kulkarni, Pradeep Madhavarapu, Isima with inputs from Ryan Metz, Rahul Unnikrishnan Nair, Intel

Introduction
In the early 90s, Intel ran a campaign1 about spotting the very best PCs. This decade established Intel as the undisputed leader in microprocessors. 30 years later, engineers at Intel and Isima decided to attempt the same for data and analytics. Read on to learn more.
Strategic focus
“…to be competitive, …, in the cloud space, we need to bring a software-first focus”
CEO, Intel, CRN
Under Pat’s leadership, Intel has embarked on a software-first strategy. And there is no better software validation than analytics – the killer app of the cloud that also happens to consume the most effort (people and time), data-center space, and watts. So Isima decided to validate what a converged offering can deliver with help from Intel engineers.
Deployment and use-case
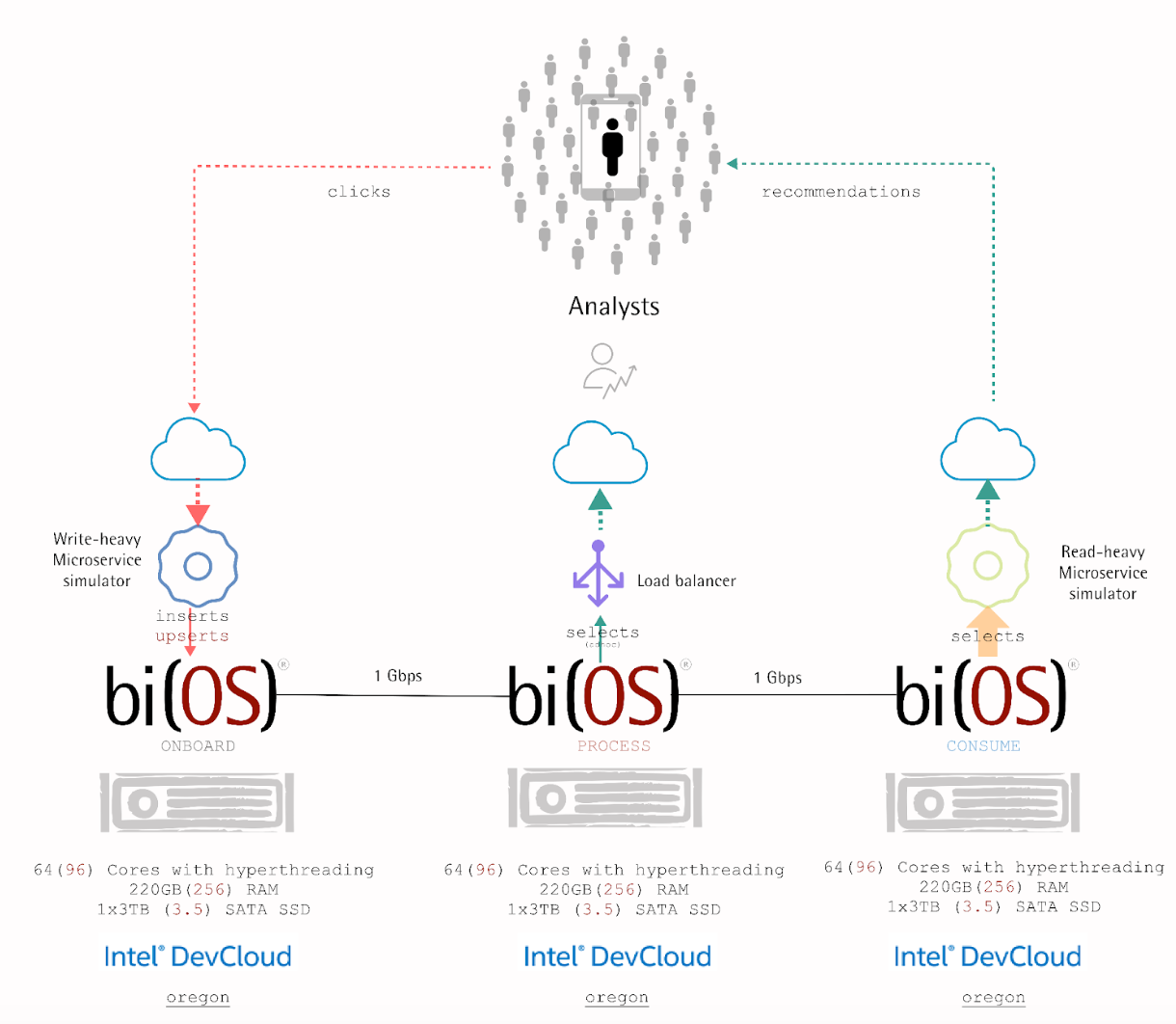
Within days, the Intel oneAPI startups program, that Isima is a member of, provided a 4-node bare-metal system from the Intel Developer Cloud, with the following specifications –
- Compute – Dual-socket 96 Cores with hyperthreading
- Memory – 256GB
- Storage – 3.5TB SATA SSD
- Network – 1 Gbps
On this system, Isima’s team deployed a KVM hypervisor emulating 2 physical sockets with the following characteristics –
- Compute – 64 Cores with hyperthreading
- Memory – 220GB
- Storage – 3TB SATA SSD
- Network – 1 Gbps
Within 36 hours2 of getting SSH access, bi(OS) was up and running on this system, simulating a real-time eCommerce recommendation engine for 2 tenants with the following metrics –
| Operations | inserts | upserts | selects |
| Throughput (rows/sec) |
~5200 | ~480 | ~1596803 |
| Avg. Latency (ms.) |
~25 | ~40 | ~160 |
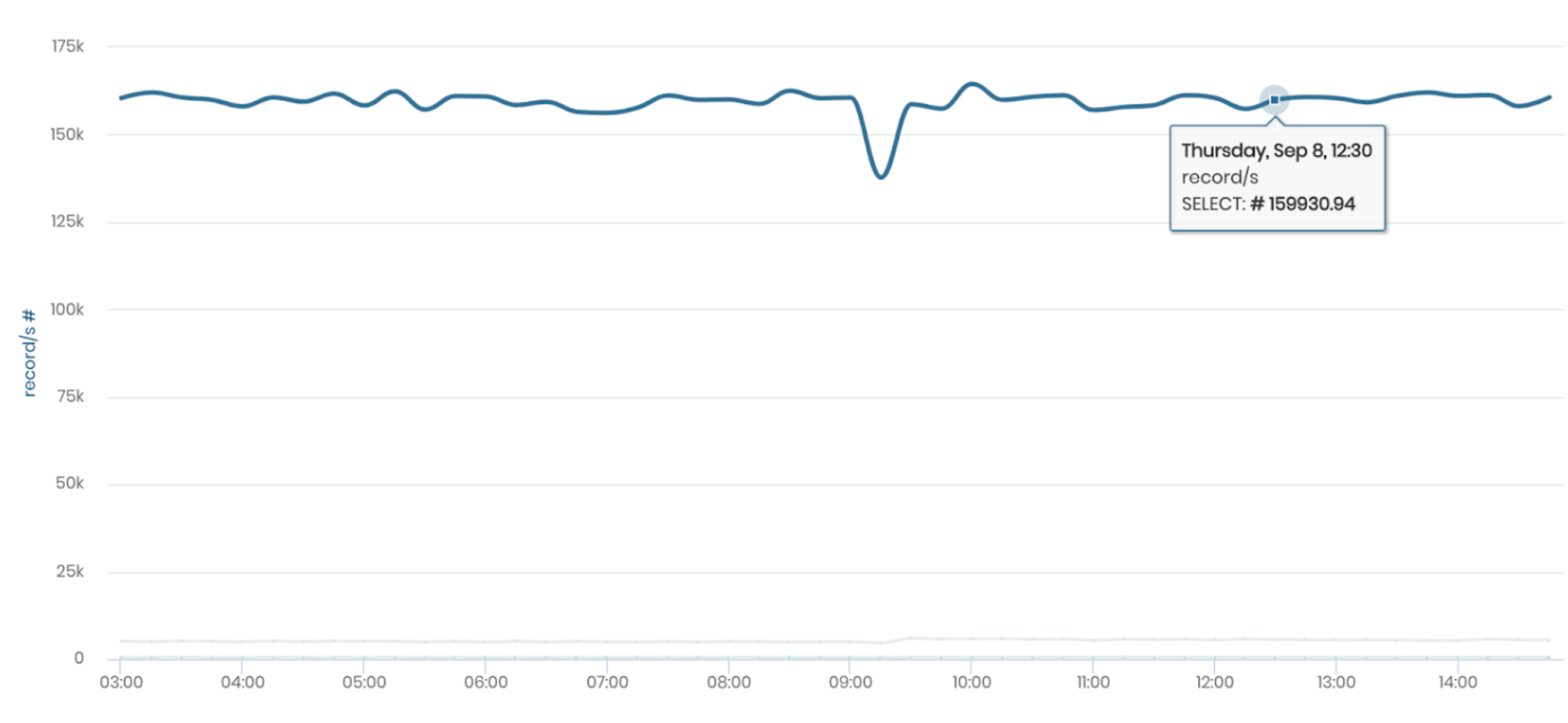
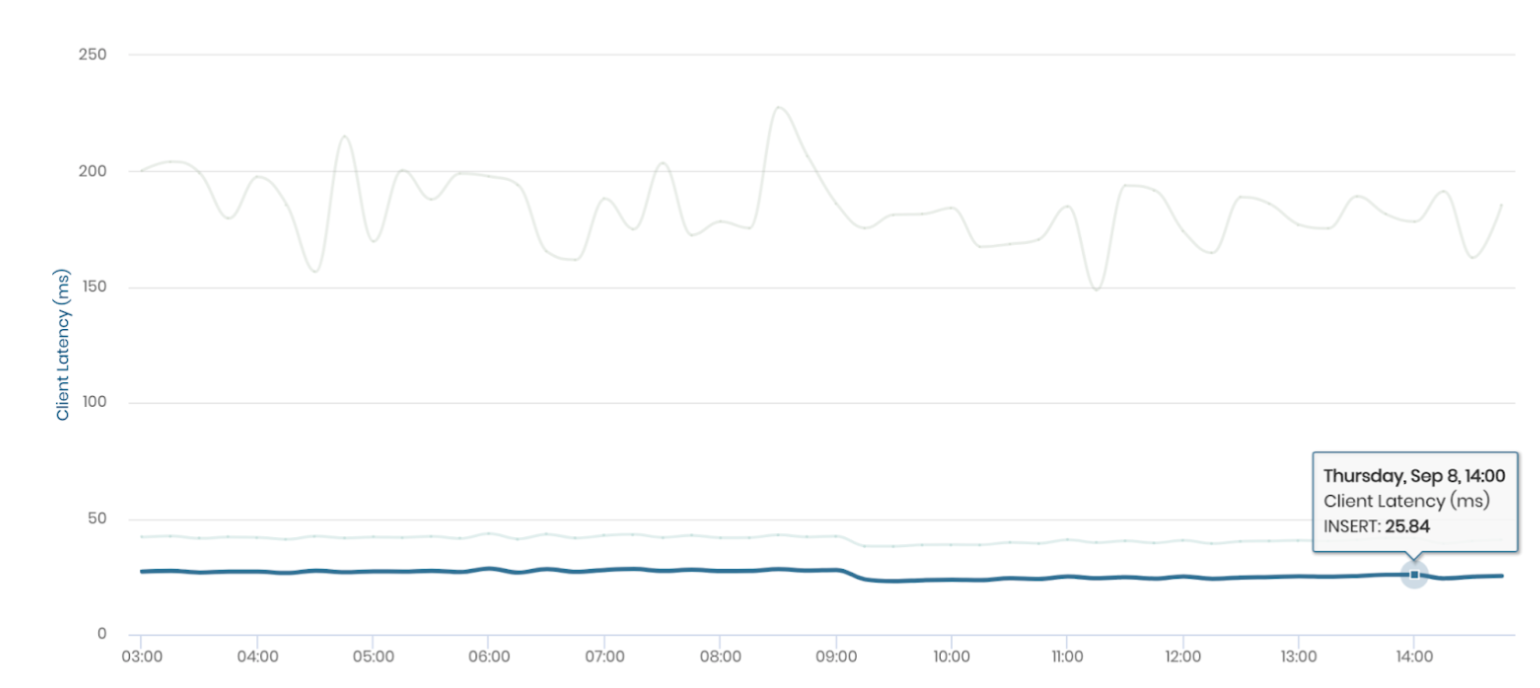
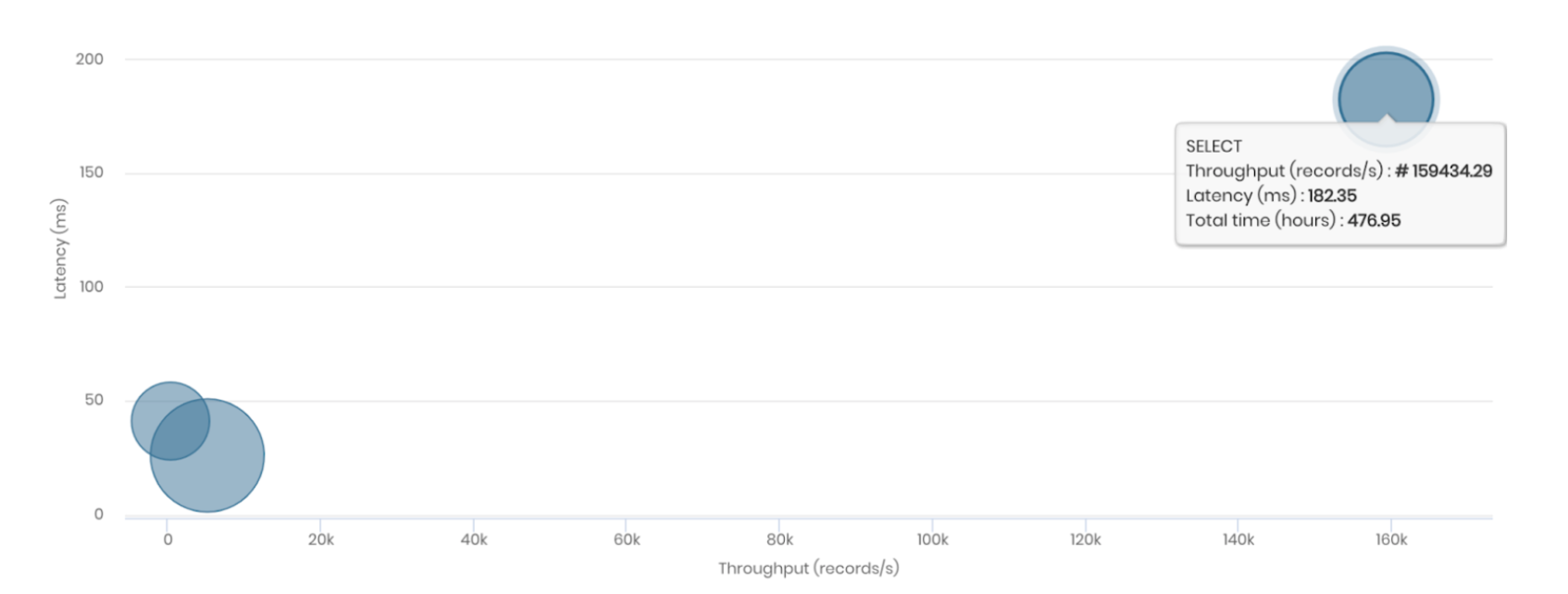
The above metrics were collected after a 7-day run with above 5 9’s reliability. bi(OS) also provided out-of-the-box observability metrics, for CPU, network and IO utilization. Some visual insights from bi(OS) are below.
Throughput
Latency
Utilization
This is a flavor of what is possible when cutting-edge infrastructure meets hyper-converged analytics.
Next Steps
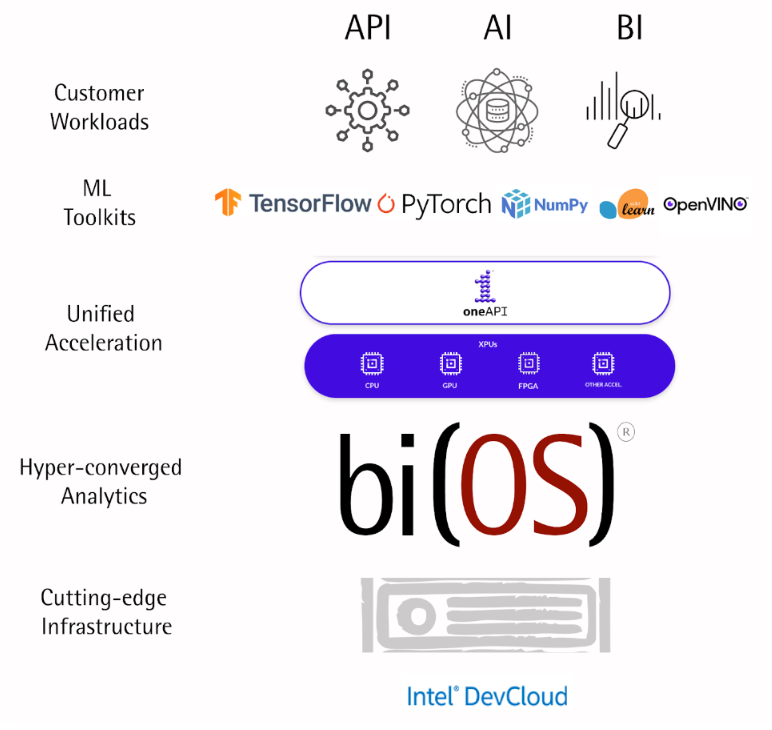
Intel’s oneAPI is a unified model and libraries for accelerated computing. It has been integrated with major ML frameworks such as TensorFlow, PyTorch, and NumPy and packaged in various ways for all major Operating systems including as docker containers4. We plan to certify oneAPI and bi(OS) for eCommerce workloads on next generation Intel® Xeon® Scalable Processors in a few weeks.
Conclusion
“…delivering silicon that isn’t supported by software is a bug,”
CEO, Intel, CRN
Analytics is the killer app of the cloud. It also consumes the most resources — effort (people and time), data-center space, and watts — scarce resources in the current economic environment. Optimizing bits and human productivity can unleash a quantum leap in analytics impact, especially for industries that don’t have an ad-subsidized infinite checkbook to fund the cloud inefficiencies. This is what Intel + Isima are attempting to solve, to unleash a giant leap in cloud economics while helping the climate.
About oneAPI
oneAPI5 is an open, cross-industry, standards-based, unified, multi architecture, multi-vendor programming model that delivers a common developer experience across accelerator architectures — for faster application performance, more productivity, and greater innovation. The specification consists of ten core elements – DPC++, oneDPL, oneDNN, oneCCL, Level Zero, oneDAL, oneTBB, oneMKL, oneVPL and Ray Tracing. The oneAPI specification is open-source5, and the initiative encourages collaboration on the spec and implementations across the accelerator ecosystem. One example of collaboration is TensorFlow, an end-to-end open-source software platform for machine learning, now ships with the oneAPI Deep Neural Network Library (oneDNN), a Neural Network acceleration library as the default backend for CPUs6.
About bi(OS)
Isima’s bi(OS) is a lean modern data stack to onboard, process, consume and operate data using Clicks, Python, and SQL. Its hyper-converged architecture enables real-time use cases with a low-code framework. This allows a single data analyst to bring API, AI, and BI use cases to life in days, radically reducing time to value with the best price-performance on the cloud.
Note – Intel, Intel inside and Intel oneAPI are trademarks of Intel Corporation in the U.S. and other countries. All third-party marks are property of their respective owners.
.
2. This included teething pains, setting up KVM, SSH tunneling, installing bi(OS) and starting the load. All on a Labor-day weekend.
3. Each select returned ~700 rows and we achieved 250 select queries/sec.
4. https://hub.docker.com/r/intel/oneapi.
5. https://www.oneapi.io.
6. https://www.intel.com/content/www/us/en/newsroom/news/intel-onednn-speeds-ai-optimizations-in-tensorflow.html.